
Author: Ge Wang
The Clark & Crossan Endowed Chair Professor and Director of the Biomedical Imaging Center at Rensselaer
For diagnosis, ancient Chinese physicians use four steps: observing, listening/smelling, asking, and palping. By observing the tongue and skins, an ancient doctor could extract information on a patient’s health status. Indeed, we have impressions on many things mostly by our sight. Modern medicine heavily relies on high-tech imaging devices such as computed tomography (CT) and magnetic resonance imaging (MRI) scanners that are “super eyes” deeply peeking into the human body and non-invasively making cross-sectional images of internal organs. Since pathological features are small at an early stage, we want to have as clear as possible CT and MRI images that show small features and even subtle details. However, the higher the requirements on the image clarity, the more complicated the imaging scanner needs to be, and the more expensive the health-care expense.
Can we somehow make an existing medical image clearer? Making an image clearer, sharper, or better in other ways, is not a new idea. Over the past decades, a branch of science and technology called “image processing” has been extensively studied to digitize an image and then process it with a digital computer using an image processing method (also known as an algorithm). Image processing transforms an image into an improved form in which image features are presented more favorably, such as with boundaries highlighted or noise suppressed. Making an image clearer overall and closer to the ground truth is a special topic of image processing, called deblurring or super-resolution imaging (some researchers think deblurring and super-resolution are the same: Deblurring makes a blurred image clearer with the same image pixel size, while super-resolution imaging reduces the image pixel size for the same field of view so that the image looks clearer. Since these two tasks are closely related, in this blog article we use these two words without distinction). Here “resolution” is a technical term expressing how closely small targets can be put together while they can still be visually separated in an image of interest. Then, “super-resolution” imaging means something we could do via image processing so that an image from the system can be made in a resolution better than the original resolution of an imaging system.
Figure 1. Imaging blurring is caused by an imperfect imaging system, and can be (to some degree) undone via computational deblurring.
For computation, we essentially perform four operations: addition, subtraction, multiplication, and division. Roughly speaking, these operations are in terms of numbers in primary schools, variables in high schools, and so-called “operators” in colleges and universities (Figure 1). When a real imaging system is used to image a tiny bright object, it will appear as a blurring dot in the resultant image since no imaging system is perfect in depicting a real-world object. This blurring process can typically be formulated as a “convolution” operation. A convolution is actually a multiplication in disguise, which is a special multiplication of an involved object and the imaging system characteristics. Hence, deblurring must be done by a special division that compensates for the convolution. However, features are compromised in the blurring process, or even eliminated (equivalent to setting some features to zero). Hence, it is rather challenging to rescue damaged features (think about it: how can you use zero as denominator?).

Figure 2. Our imagination can easily fill in the blocked parts of a horse; so could a computer after being equipped with a deep learning network.
Recently, machine learning, especially deep learning, has become an extremely hot topic, given its tremendous successes in image processing and computer vision (to let a robot or a computer equipped with a camera perceive what we can). Our human vision system is amazing. When you see a blocked horse in a forest, you can perceive the horse in its entirety (Figure 2). In that case, you can do so because you have extensive knowledge of trees and horses and reasoning power in the context, and you can infer confidently what the blocked features of a horse would be.
This visual perception can now be achieved via image processing using deep learning techniques. Specifically, a deep artificial neural network can be designed and trained to mimic our biological neurological network responsible for vision, using a big dataset consisting of numerous pairs of low-quality (blocked or otherwise compromised) and corresponding high-quality images (unblocked horses). After training the deep artificial neural network, it becomes an expert in this application domain: whenever a low-quality image is presented to the network, it will process the image with interconnected artificial neurons (which are basic computing units) in the network, and finally deliver a high-quality counterpart (for example, a partially blocked horse can be brought up to the foreground with its natural appearance)!
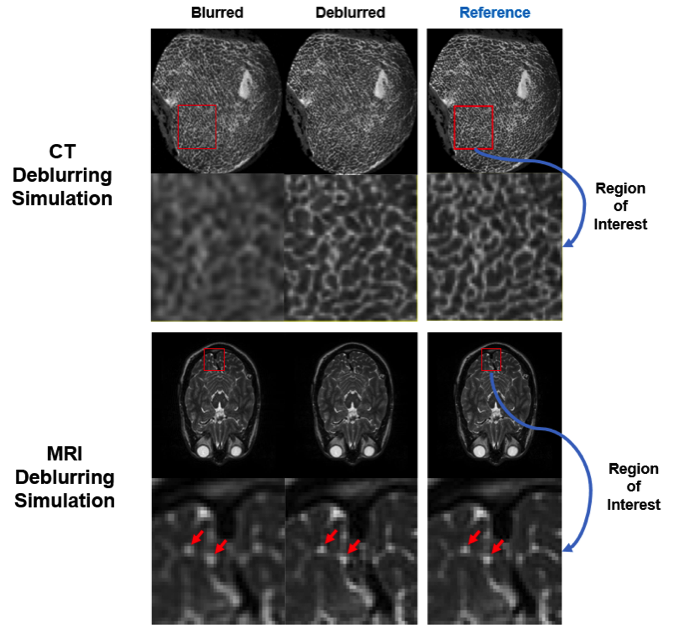
Figure 3. Our initial simulated CT and MRI super-resolution results, which suggest 100% to 200% resolution improvements.
In 2016, our team wrote a perspective on deep-learning-based imaging, which is a basis for an IEEE Transactions on Medical Imaging special issue on this theme and our application of a machine learning-based imaging patent. In this perspective, we presented a machine-learning-based super-resolution imaging example. Recently, our biomedical imaging center posted two arXiv papers to improve medical CT and MRI images towards super-resolution (https://arxiv.org/abs/1808.04256; https://arxiv.org/abs/1810.06776). While traditional deblurring methods could only improve CT or MRI image resolution by a modest fraction, deep learning methods can do much better, with 100 percent or even 200 percent resolution improvement in our preliminary simulation studies (Figure 3).
We are actively working along this line, such as for micro-CT and micro-MRI, and optical microscopic imaging. In a nutshell, super-resolution deep learning could computationally turn a cheap imaging device into a decent one by making existing images clearer. The economical and biomedical implications of this approach are tremendous; for example, useful for diagnosis of cancer, brain tumors, or other pathologies. We welcome new collaborative or application opportunities in this area!


